Infrastructure Crack Day: When Your Automation Ghosts You
The Morning Won, The Pipes Lost
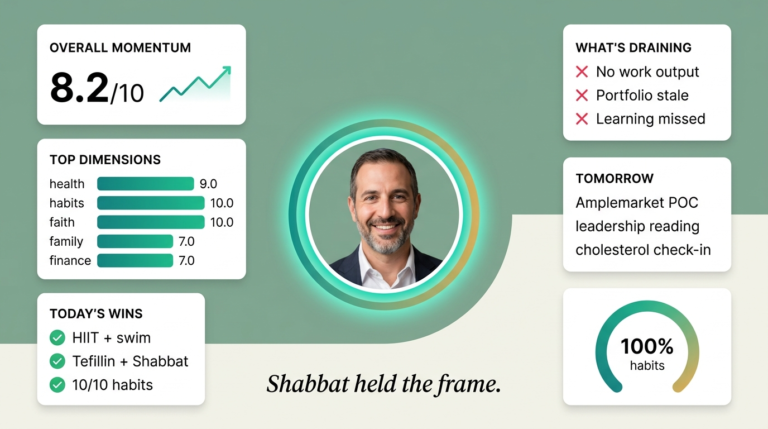
Today was a 4.6/10, and I need to be honest about why. Not because everything collapsed—it didn’t—but because the invisible infrastructure I’ve been building to run while I sleep started failing *silently*, and that’s worse than a loud crash.
The morning brief executed flawlessly. Portfolio snapshot went out on time: VST down 2.1%, ASML getting hammered at -5.0%, MSFT up 4.1%, PLTR holding at +3.0%. News intel fresh. Asana status clean. That’s the win. That’s the part that keeps the team oriented when I’m heads-down in sales calls or dealing with whatever fire is currently burning at work. The spine held.
But then the cracks showed up.
By noon, I realized: ScreenPipe didn’t report. Strava never synced. My morning cron jobs—the Morning Email, the Tomer Evening Brief, the ScreenPipe Brief, the Blog Generator, the Budget Updater—they all just… didn’t fire. And Twilio threw three consecutive 20003 errors, which means some of my outbound notifications went into the void. Nobody knows they’re missing yet, but *I* know. And that’s a different kind of problem.
Here’s the thing about building your own automation stack: when it works, you get this insane leverage. One set of code runs a hundred times a day, every day, without you thinking about it. But when it breaks, you don’t have a helpdesk to call. You *are* the helpdesk. And if you don’t notice, the system just silently fails to do the one thing it was supposed to do.
The Visibility Gap
What got to me most: I went almost an entire day without knowing whether I actually trained. No Strava data. No ScreenPipe. I *think* I didn’t move enough—I can feel it in my shoulders—but I don’t *know*. And I can’t optimize what I can’t see.
That’s the core tension I’m sitting with. I built these systems to be proactive—to surface information before anyone asks, to anticipate, to automate away the friction. But the moment my own data pipes break, I’m operating blind. I’m the SDR who can’t see his own pipeline metrics.
{
}
The Asana picture is instructive too. Marketing has 215 incomplete tasks out of 1,881. Weekly Priorities: 100 incomplete out of 878. Skilled Hunters: 12 out of 126. None of those numbers will kill us, but the *volume* is noise. I need ruthless triage. What actually moves the needle? Everything else needs to soft-archive or get delegated. I got the brief out, at least—that’s the proactive thread that held.
Tomorrow’s Contract with Myself
Here’s what I’m doing tomorrow:
- Debug the cron pipeline. Morning Email, Tomer Evening, ScreenPipe Brief—I need to know why they failed and fix it before they fail again. Silent failures are worse than loud ones.
- Restore personal visibility. Get Strava syncing again. Get ScreenPipe running. I can’t lead a team if I can’t see my own health and time-use data.
- Ruthless Asana triage. Go through those 215 Marketing incomplete tasks. Identify the top 10 that actually matter. Everything else gets soft-archived or escalated.
The deeper insight here isn’t about automation or code. It’s about the illusion of scale. You can build systems that run 24/7, that surface information proactively, that anticipate needs. But if those systems fail silently and you don’t have mirrors to see yourself, you’re just building a very elaborate trap.
Real infrastructure resilience isn’t about having a million automations running. It’s about having *visibility* into what’s actually running, fallbacks when things break, and ruthless honesty about what you can actually maintain.
Yalla. Tomorrow we fix the pipes.